Mascaramento de Dados no Oracle
Fala, turma! Tudo beleza?
Essa semana me deparei com um desafio novo e resolvi trazer aqui para compartilhar com vocês.
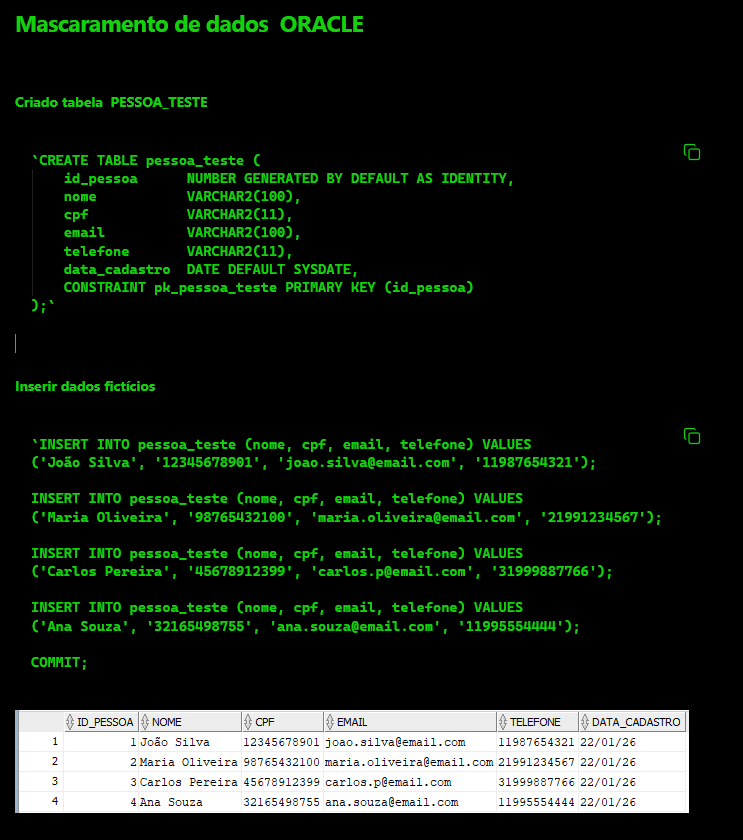
Eu precisava ocultar informações sensíveis em uma base de dados de desenvolvimento, com o objetivo de proteger dados pessoais e informações de identificação dos usuários que acessam esse ambiente.
A ideia era simples: permitir que o time continuasse usando a base normalmente, mas sem expor dados reais, como CPF, telefone e e-mail.
A partir disso, comecei a estudar algumas alternativas e acabei chegando em um conceito muito importante (e cada vez mais necessário): Mascaramento de Dados.
Neste post, vou apresentar uma visão geral sobre mascaramento de dados no Oracle, explicar os principais tipos e, ao final, mostrar como implementei uma solução prática usando function/procedure com UPDATE, passo a passo.
O que é mascaramento de dados?
Bom o mascaramento de dados é a técnica de ocultar informações sensíveis, mantendo o formato ou a utilidade do dado, mas impedindo que o valor real seja visualizado.
Exemplos de dados sensíveis:
-
CPF
-
Telefone
-
E-mail
-
Número de cartão
-
Dados pessoais em geral
Exemplo prático:
O dado continua útil para testes e consultas, mas não expõe a informação real.
Oracle Post
Tipos de Mascarametos
Mascaramento dinâmico (em tempo de consulta)
Nesse modelo, o dado original não é alterado na tabela.
O mascaramento acontece apenas no momento do SELECT.
Técnicas comuns:
-
CASE -
SUBSTR -
REGEXP_REPLACE -
VIEW
Uso comum:
-
Telas de sistemas
-
Relatórios
-
APIs
Vantagens
-
Reversível (o dado original continua intacto)
-
Fácil de implementar
Desvantagens
-
Quem tem acesso direto à tabela ainda vê o dado real
Mascaramento estático (UPDATE definitivo)
Aqui o dado é substituído por um valor falso diretamente no banco.
Exemplo:
Uso comum:
-
Bases de homologação
-
Desenvolvimento
-
Treinamento
-
Compartilhamento de dados
Vantagens
-
Irreversível
-
Muito mais seguro para ambientes não produtivos
Atenção
-
Não usar em produção sem backup
Mascaramento por VIEW
Cria-se uma VIEW com os dados mascarados e restringe o acesso à tabela real.
Uso comum:
-
Usuários de negócio
-
BI e relatórios
-
Times externos
Vantagens
-
Simples e eficiente
A segurança depende diretamente das permissões concedidas.
Mascaramento condicionado por perfil ou usuário
O dado exibido varia conforme:
-
Usuário
-
Role
-
Schema
-
Contexto de sessão
Exemplo:
-
Administrador vê CPF completo
-
Usuário comum vê CPF mascarado
Uso comum:
-
Sistemas corporativos
-
Ambientes que precisam atender LGPD
Vantagens
-
Muito flexível
Regras precisam ser bem definidas para evitar falhas.
Mascaramento com randomização
Substitui os dados reais por valores aleatórios, mantendo o formato.
Exemplos:
-
CPF fake
-
Telefone fake
-
Nome genérico
Uso comum:
-
Cópia de produção → homologação
Vantagens
-
Muito utilizado
-
Fácil de aplicar
Não preserva relacionamentos lógicos entre dados.
Mascaramento determinístico
O mesmo valor original sempre gera o mesmo valor mascarado.
Exemplo:
Uso comum:
-
Manter joins
-
Testes de integração
Vantagens
-
Preserva relacionamentos
Ainda é irreversível.
Tokenização
Substitui o dado sensível por um token, armazenando a relação em outro local seguro.
Exemplo:
Uso comum:
-
Sistemas financeiros
-
Ambientes de alta segurança
Pode ser revertido
Implementação mais complexa
Criptografia (não é mascaramento, mas complementa)
O dado é armazenado de forma criptografada no banco.
Uso comum:
-
Dados críticos
-
Compliance e segurança
Reversível com chave
Quem tem acesso ao sistema pode ver o dado descriptografado
📊 Comparativo
| Tipo | Altera dado? | Reversível? | Uso comum |
|---|---|---|---|
| Dinâmico | ❌ | ✅ | Telas / relatórios |
| Estático | ✅ | ❌ | Homolog / Dev |
| View | ❌ | ✅ | Usuários finais |
| Por perfil | ❌ | ✅ | Sistemas |
| Randomizado | ✅ | ❌ | Testes |
| Determinístico | ✅ | ❌ | Integração |
| Tokenização | ✅ | ✅ | Alta segurança |
| Criptografia | ✅ | ✅ | Compliance |
Qual abordagem escolher?
-
Produção / LGPD → Mascaramento dinâmico + controle de acesso
-
Homologação / Dev → Mascaramento estático
-
Dados financeiros → Tokenização ou criptografia
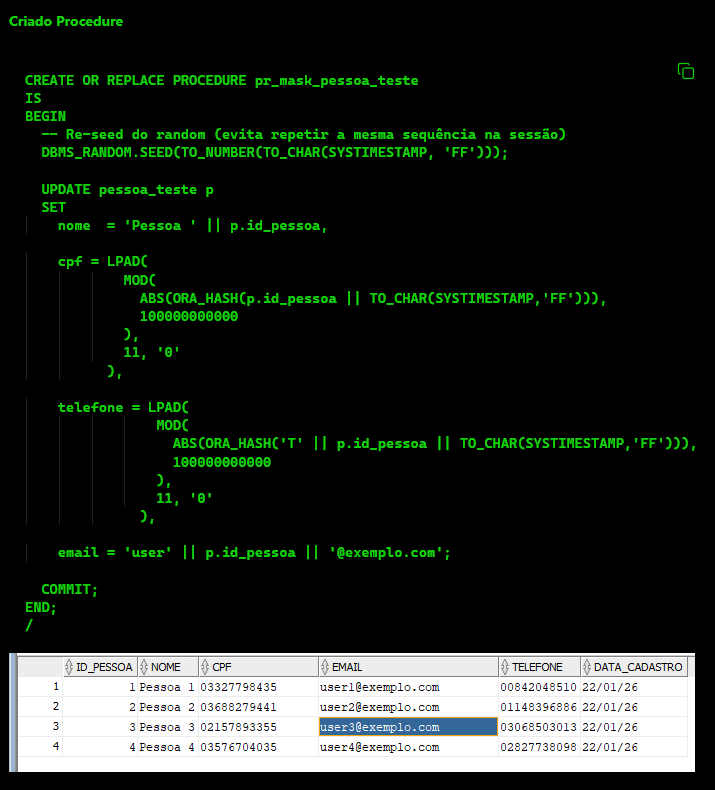
Minha escolha: mascaramento estático com UPDATE
Neste cenário específico, optei por implementar um mascaramento estático, criando uma function/procedure com UPDATE, que substitui os dados sensíveis por valores fictícios diretamente na tabela.
No próximo trecho, vou mostrar:
-
por que escolhi essa abordagem
-
como criar a procedure
-
como executar passo a passo
-
e como validar o resultado
Passo a Passo: